
印刷物から文字を起こすときに便利な方法備忘録
キーパンチャーじゃないからブラインドタッチできないからうまくやる方法を模索。
一時期なくなったGoogleの機能でさらに楽に抽出できるようになりました。
それと以前は「翻訳」のツールで「日本語」→「日本語」にすれば抽出できる裏技があったのですが、同言語選択の機能ができなくなったのでこちらをお勧めします。
ドラッグ&ドロップで簡単にUPできます。
複数画像も一気にUPできます(時間がかかるけど)
画像を選択してからマウスの右をクリックして出てきたメニューから
「アプリで開く」→「Googleドキュメント」を選びます

一応ぐるぐると動くアニメーションが表示。
もしここで止まっているようだったらブラウザ(edgeやchrome)を閉じて再度Googleドライブにアクセスすると画像と同じ名称の「ドキュメント」のファイルが出来上がっている場合があります。

なぜか画像が逆さになったりします…が、気にしない。

もちろんコピペできます!
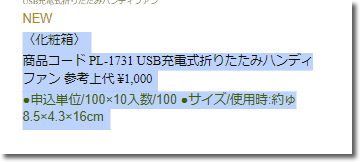
結構な時間の短縮になるので便利です。
数字は、ほぼ間違いない感じです。
漢字については結構中国語寄り。まぁ仕方ないです。
今回はカタログを写メしたものを使用したのですが、光の反射や背景がなければもっとしっかりと採れた感じがします。
無地の部分に文字が望ましい感じで、白地に黒文字は確実に取得可能。逆に白ヌキ(色地に白文字)でも大丈夫でしたのも驚きです。
グレーの下地に黒文字のような類似カラーは苦手なようです。

結果はコレです。
ダメダメでした。
そもそも字が汚いということもあるのですが閉じるところは閉じる、跳ねるところは跳ねるをしっかりすれば大丈夫なのかもしれません…(先生みたいだな…><)
2025 記念品ストアー